
When tech failures hit, how you communicate matters as much as fixing the issue. Companies that provide clear, timely updates during outages maintain trust and reduce fallout. Silence, jargon, or inconsistent messaging can escalate a manageable problem into a reputation crisis.
Key takeaways:
- Acknowledge issues quickly: Speed matters more than perfection.
- Tailor updates to stakeholders: Engineers need technical details; customers want plain language.
- Avoid common mistakes: Silence, jargon, premature fixes, and over-communication can harm trust.
- Learn from past incidents: Fastly’s quick updates and transparency worked; PagerDuty’s silence didn’t.
Prepare now: Identify stakeholders, set communication cadences, and create templates. Effective communication isn’t just damage control – it builds trust for the future.
Tech Failures and Stakeholder Communication: Key Definitions
What Counts as a Tech Failure?
Not every glitch qualifies as a tech failure that demands formal communication. We’re talking about major disruptions – things like full service outages, security breaches, data loss, critical bugs, or noticeable performance issues like slow load times or high latency. For instance, imagine a payment system crashing during peak shopping hours, a ransomware attack locking employees out of essential systems, or a database connection pool maxing out under heavy traffic. These are the kinds of incidents that require immediate action.
The severity of a failure is typically gauged by two main factors: what functionality is affected and how long the disruption lasts. Companies often use a four-tier scale to classify incidents, ranging from P1 (Critical) to P4 (Low), with thresholds based on metrics like error rates, the number of users impacted, and the estimated time to fix. For example, a brief outage under five minutes might not need external communication. However, if critical functions like authentication or payment systems are down, stakeholders need to be informed promptly.
"When production breaks, stakeholder management determines whether your organization maintains trust or creates chaos." – upstat.io
Who Are the Stakeholders?
When a tech issue arises, stakeholders aren’t just a single group with shared concerns – they’re a mix of audiences with distinct priorities and information needs. Treating them as a monolith is a common misstep. Many startup tech leaders have shared how they navigate these complex organizational dynamics during crises.
Here’s a breakdown of key stakeholder groups and what they care about most during an incident:
| Stakeholder Group | Primary Concerns | Update Frequency |
|---|---|---|
| Executive Leadership | Revenue impact, brand risk, regulatory exposure | Every 30–60 minutes |
| Engineering Teams | Root cause details, logs, system dependencies | Real-time / Every 5–15 minutes |
| Customer Support | Talking points, workarounds, customer-facing issues | Every 15–30 minutes |
| External Customers | Data safety, feature availability, restoration ETA | Every 15–30 minutes |
| Partners & Vendors | API status, integration health | Initial notice plus updates on major changes |
| Regulators | Legal compliance, data protection standards | As required by law |
This tailored approach ensures every group gets the updates they need, in the way they need them. Engineers focus on technical details, executives need the big-picture impact, customers want reassurance, and support teams require clear, actionable scripts. Known as the Three-Layer Communication model, this method keeps internal teams aligned, business stakeholders informed, and external messaging on point.
sbb-itb-772afe6
How to Communicate During a Cyber Attack
Why Communication Breaks Down During Tech Incidents
Before diving into strategies for better communication, it’s important to understand why things often go wrong during tech incidents. These missteps not only disrupt resolution efforts but also lead to far-reaching consequences, making it essential to address them head-on.
Common Communication Mistakes
Even with well-thought-out plans, communication can crumble under the pressure of a live outage. Stress, confusion, and urgency often lead to avoidable errors.
Silence is the most damaging mistake. When updates are missing, uncertainty takes over. This fuels speculation and floods support teams with "is it down?" tickets, diverting resources from solving the actual problem. As the UpStat Editorial Team notes:
"Going silent damages trust more than acknowledging difficult problems." – UpStat Editorial Team
Other common pitfalls include context switching and jargon mismatch. Context switching – pausing to send manual updates during troubleshooting – can add 10–15 minutes to the Mean Time to Resolution (MTTR) for each incident. Meanwhile, sharing overly technical details like stack traces or microservice diagnostics with non-technical stakeholders only creates confusion. Executives and customers need to understand the business impact, not the technical specifics.
Inconsistent messaging is another frequent issue. When updates on internal platforms like Slack contradict public status pages, stakeholders lose trust and confidence. A related problem is premature resolution, where incidents are declared fixed before the solution has been fully validated. If the issue resurfaces, the resulting credibility damage is often worse than the original outage.
Here’s a quick breakdown of these mistakes and their ripple effects:
| Communication Mistake | Stakeholder Impact | Organizational Consequence |
|---|---|---|
| Delayed or no updates | Anxiety, speculation | Surge in support tickets |
| Technical jargon | Confusion | Poor decision-making at the executive level |
| Inconsistent messaging | Distrust | Chaos, duplicated efforts |
| Premature resolution | Confidence loss | Credibility damage on recurrence |
| Over-communication | Alert fatigue | Critical alerts get ignored |
The Cost of Poor Communication
The fallout from poor communication during incidents isn’t just limited to the immediate crisis – it can have lasting consequences. In the short term, engineers are pulled away from resolving the issue to handle status inquiries, while teams may act on outdated or inaccurate information, leading to wasted effort and duplicate investigations.
The long-term effects are even more severe. Customers left uninformed during outages may lose trust in the product and start looking for alternatives. Repeated communication failures can harm relationships with partners and investors. In cases involving data breaches, the stakes are even higher. For example, Equifax’s delayed and poorly managed response to its 2017 breach resulted in over $700 million in fines and ongoing legal challenges.
"Silence is what turns a normal outage into a reputation event." – FAQpages
Operational inefficiencies also come into play. Around 51% of U.S. businesses lack formal incident response plans. Without a clear plan, teams are forced to improvise under pressure, which often leads to mistakes. On the flip side, 98% of organizations with established communication plans report that these plans are effective during crises. This stark contrast underscores why a proactive approach to incident communication is so critical.
Understanding these common missteps and their consequences lays the groundwork for developing a solid, research-backed communication strategy for tech incidents.
Research-Backed Principles for Talking to Stakeholders During Incidents
Research highlights three key principles – Transparency and Accountability, Adjusted Messaging, and Feedback Loops – that distinguish successful incident communication from poorly managed responses. Let’s break each one down.
Transparency and Accountability
When an incident occurs, the first and most crucial step is to acknowledge it – quickly. Speed matters more than having all the details. As the Calmo Best Practices Guide explains:
"Speed trumps perfection here – Google’s SRE teams stress that quick acknowledgment works better than waiting for complete information."
A simple acknowledgment signals action, even if the details are still unclear. For critical incidents, aim to provide updates every 20–30 minutes, even if there’s nothing new to report.
Two points to prioritize early on: don’t downplay the severity and be clear about data integrity. For example, calling a significant outage "intermittent" can destroy trust. Customers’ primary concern often isn’t "when will this be fixed?" – it’s "is my data safe?" Address that directly and upfront.
While speed and clarity are essential, tailoring your message to different audiences ensures you avoid miscommunication.
Adjusting Messages for Different Audiences
Effective communication isn’t one-size-fits-all. Tailoring your updates to fit the needs of different stakeholders builds trust and prevents confusion. The Three-Layer Communication Model is a practical way to structure this:
- Layer 1 (Internal/Technical): Share real-time diagnostics – logs, stack traces, attempted fixes – with engineering teams every 5–15 minutes.
- Layer 2 (Business/Executive): Provide summaries focused on risks to revenue, SLA exposure, and resource allocation, updated every 30–60 minutes.
- Layer 3 (External/Customer): Use plain language to explain the issue, what’s being done, and when resolution is expected. These updates should also go out every 30–60 minutes.
Before sending messages to executives or customers, strip out technical jargon like "Kubernetes", "pod", or "database connection pool exhaustion." Replace these with simpler terms like "system overload" or "service disruption". For support teams, create specific talking points and workarounds they can use when fielding customer calls.
Building Feedback Loops
Two-way communication is critical during incidents. Allowing stakeholders to share concerns while providing timely responses helps prevent the situation from spiraling into a broader crisis.
Set up two key communication channels: an internal "war room" for technical teams and a separate broadcast channel for updates. This separation avoids context switching, which can delay resolution by 10–15 minutes. Assign a dedicated Communications Lead – someone separate from the Incident Commander – to translate technical updates into stakeholder-friendly messages.
After the incident, conduct a structured review within 24–48 hours while details are still fresh. Use this session to identify communication gaps and refine response templates for future incidents. This feedback process not only improves recovery times but also strengthens the transparent practices outlined earlier.
Lessons from Past Tech Incidents
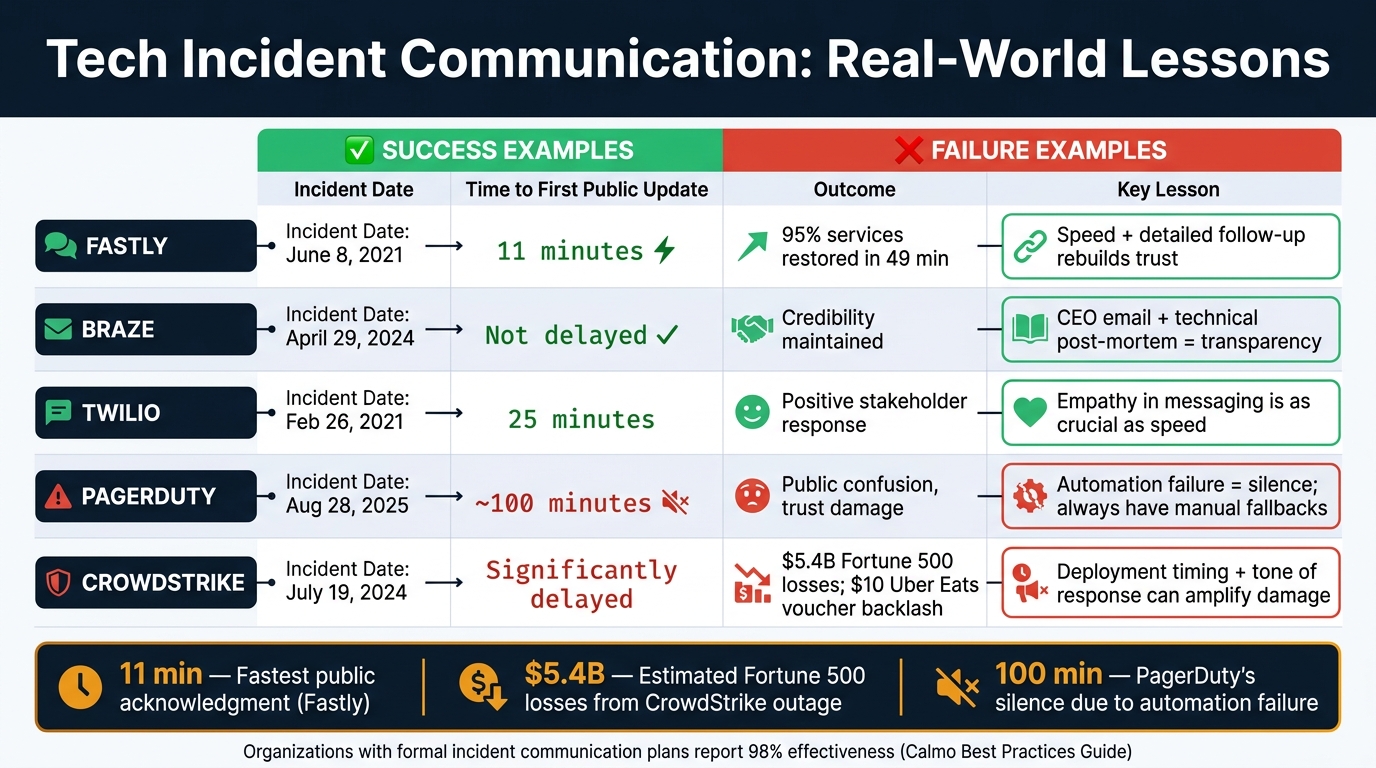
Tech Incident Communication: What Works vs. What Fails
Looking at real-world scenarios, it’s clear that past tech incidents offer valuable insights into both effective and flawed communication strategies. These examples highlight what works – and what doesn’t – when it comes to managing crises. Many tech leaders have shared similar stories of navigating these high-stakes moments.
What Good Communication Looks Like
A standout example of effective communication is Fastly’s global outage in June 2021. When a previously undetected software bug – triggered by a single customer’s configuration change – caused 85% of its network to fail, Fastly acted fast. Monitoring systems identified the problem at 09:48 UTC, and just 11 minutes later, the company issued a public update. Within 49 minutes, 95% of services were back online. Fastly didn’t stop there. They later published a detailed blog post explaining the root cause, tracing it to a software deployment from May 12. This transparency gave customers a clear understanding of what went wrong and how it was fixed.
Another strong example comes from Braze‘s April 2024 outage, which lasted nearly 11 hours due to a "broadcast storm" caused by a network loop at a Rackspace data center. Instead of relying solely on status page updates, CEO Bill Magnuson personally emailed all dashboard users during the incident. CTO Jon Hyman followed up with a technical post-mortem on May 3, 2024, explaining the Cisco Nexus switch failure and the need to restart 16,000 mongoD processes. Hyman’s candid statement set the tone:
"We know that we only have one opportunity to be honest and forthright about what is occurring, and that transparency about incidents – both in the moment and following their resolution – is essential to maintain trust."
By combining executive-level communication with a detailed technical explanation, Braze demonstrated how to maintain credibility during a crisis.
While these examples show how to handle incidents well, others reveal common pitfalls to avoid.
Communication Mistakes to Avoid
PagerDuty’s Kafka outage in August 2025 is a prime example of the dangers of over-relying on automation. When cascading Kafka failures disrupted event processing across US Service Regions, their automated status update system also failed. This led to 100 minutes of public silence, even as internal teams scrambled to draft updates that never went live. Compounding the issue, 18 of 19 high-urgency pages were downgraded to low-priority webhook notifications, burying critical alerts. PagerDuty later admitted:
"Our internal and external communications during the incident were not well aligned… These lapses led to avoidable confusion about the outage’s status."
Another cautionary tale comes from CrowdStrike‘s July 2024 incident, where poor deployment timing and an inappropriate response amplified the fallout. On July 19, 2024, a buggy "Rapid Response Content" update rolled out globally, causing 8.5 million Windows devices to crash with the Blue Screen of Death. The timing couldn’t have been worse – it was a Friday, when IT staffing is typically limited. The financial impact was enormous, with Fortune 500 companies losing an estimated $5.4 billion, including $500 million from Delta Air Lines alone. CrowdStrike’s attempt to apologize with $10 Uber Eats vouchers was widely criticized as tone-deaf, given the scale of the disruption. This incident serves as a reminder that both the timing of deployments and the tone of responses matter greatly.
These examples underline the importance of thoughtful, audience-focused communication during crises.
| Company | Incident Date | Time to Public Update | Key Lesson |
|---|---|---|---|
| Fastly | June 8, 2021 | 11 minutes | Speed and detailed follow-up rebuild trust |
| Braze | April 29, 2024 | Not delayed | CEO email and technical post-mortem reinforce credibility |
| Twilio | Feb. 26, 2021 | 25 minutes | Empathy in messaging is as crucial as speed |
| PagerDuty | Aug. 28, 2025 | ~100 minutes | Automation failure leads to public silence; manual fallbacks are key |
| CrowdStrike | July 19, 2024 | N/A | Deployment timing and response tone can amplify damage |
A Step-by-Step Framework for Incident Communication
When incidents strike, even seasoned teams, like those featured on our podcast archive, can struggle to communicate effectively under pressure. That’s why having a clear, actionable framework is essential. By focusing on transparency and crafting messages suited to each audience, you can keep stakeholders informed without adding chaos to an already stressful situation.
Mapping and Prioritizing Stakeholders
Before anything goes wrong, it’s critical to identify who needs updates and what type of information they require. Group stakeholders into tiers based on their roles and priorities, ensuring communication is tailored to each group’s needs. This approach builds on the Three-Layer Communication Model by defining roles and update frequency for each stakeholder category.
The severity of the incident should determine who gets notified. For SEV1 incidents, engineers, executives, customer success teams, and the public should be alerted immediately. In contrast, lower-severity issues might only require internal notifications. Pre-defining these thresholds eliminates guesswork during a crisis.
Another key step? Assigning a dedicated Communications Manager. This person handles translating technical updates into clear messages, freeing up engineers to focus on solving the problem.
Setting a Communication Cadence
One of the biggest mistakes during incidents is silence. Regular updates are vital, even if there’s no new information to share. For example:
- External customers should receive updates every 20–30 minutes.
- Executive leadership should be informed every 30–60 minutes.
- Internal engineering teams need near real-time updates.
Every message should end with a clear timestamp for the next update, such as: "Next update at 3:30 PM ET." This practice reduces unnecessary follow-up questions, allowing response teams to stay focused.
"The solution isn’t ‘better discipline’ or ‘remember to update more often.’ The solution is treating communication like code: automated, templated, and reliable." – Tom Wentworth, CMO, incident.io
To simplify communication during high-pressure moments, use pre-written templates tailored to different severity levels. This ensures consistency and reduces the mental burden on team members.
Post-Incident Review and Improvement
Once the dust settles, a post-incident review is crucial. Conduct this review within 24–48 hours of resolution. The goal is to identify and address any gaps in the communication process. For example, ask questions like: When was the first update sent? Were any stakeholder groups overlooked? Were updates delayed or unclear?
Different audiences will need different post-mortem formats. Engineering teams require technical details, executives need a summary of business impacts, and customers deserve a straightforward explanation, an apology, and a plan for preventing future incidents.
Use these reviews to refine playbooks, improve templates, and adjust escalation thresholds. Every incident is an opportunity to strengthen your communication process for the future.
Conclusion: How Clear Communication Builds Long-Term Trust
Tech failures are bound to happen. What sets successful organizations apart isn’t avoiding outages altogether – it’s how they handle communication when issues arise.
Since downtime is inevitable, the way you communicate during these moments becomes your defining factor. Studies reveal that silence during a crisis can cause more damage than the technical failure itself. Stakeholders are often willing to forgive a technical hiccup, but being left uninformed is harder to overlook. Take the 2017 Equifax breach as an example – delayed communication led to hefty financial consequences, proving that poor communication can come at a steep price. On the other hand, organizations with formal incident communication plans report success 98% of the time, with 77% calling them "highly effective".
Clear and consistent updates, tailored to your audience, go beyond damage control – they foster trust. These practices not only help you weather the storm but also strengthen your relationships with stakeholders.
"Educated clients stay. Confused clients leave." – Jason Mudd, CEO/Founder, Axia Public Relations
The takeaway? Start building your communication strategy now. Map out your stakeholders, draft templates, and create a playbook before any issues arise. Being prepared allows you to turn crises into moments where you can showcase your organization’s resilience and operational excellence.
FAQs
When should an issue be communicated publicly?
Public communication becomes essential when an issue has a major impact on stakeholders, erodes trust, or interrupts normal operations. Sharing updates promptly and openly can help preserve confidence and address the situation more effectively.
Who should own incident updates during an outage?
The communications lead plays a key role during an outage, ensuring that incident updates are handled effectively. Their responsibilities include crafting clear messaging for stakeholders, translating complex technical details into language that aligns with business needs, and providing accurate, timely updates tailored to various audiences. This role is crucial for maintaining transparency and trust during high-pressure situations.
What should a first outage update include when details are unclear?
When a tech outage occurs, the first update plays a crucial role in setting the tone. It should acknowledge the incident and confirm that an investigation is already in progress. This approach helps manage expectations and stops rumors or misinformation from spreading. Even if specific details aren’t available yet, being upfront and transparent is essential to keeping stakeholders’ trust intact during such situations.